



When designing a distributed system (one of the most favourite aspect of technical interviews, mid-senior level onward), these are the key non-functional areas that need your attention:
- Scalability
- Reliability
- Availability
- Efficiency
- Manageability
1. Scalability
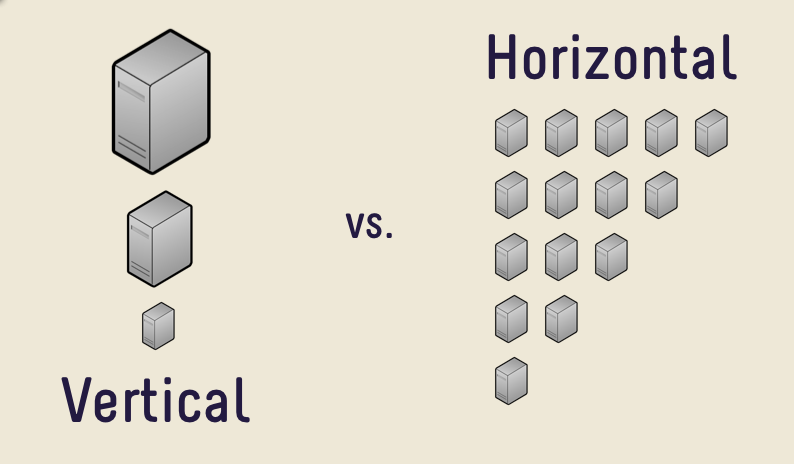
Scalability is the ability of a system to incorporate the growing demands (increasing user base, more requests per second, etc) such that its performance does not take a hit. There are two ways to implement this:
- Horizontal scaling: adding more machines/servers into the pool of resources. HS is easier to achieve. Data stores like Cassandra and MongoDB facilitate it.
- Vertical scaling: increasing the capacity of the existing servers by adding more power (CPU, RAM, storage). VS is limited to the capacity of a single server and trying to scale beyond that often involves system downtime. An example of VS can be found in MySQL.
2. Reliability
Reliability is determined by computing the probability of a system failure in a given period of time. A distributed system is deemed reliable if it keeps delivering its services even when one of its hardware/software components fails.
This is achieved with the help of data redundancy - which has its own cost. The aim here is to eliminate every single point of failure by keeping multiple instances around, which can be used to replace the failing instance.
Availability
Availability is a measure of the amount of time a system, service, or machine remains operational under normal conditions. Availability considers maintainability, repair time, spare availability, and other logistics. A system down for maintenance won’t be considered available during that time.
Reliability vs availability, if a system is reliable, it will be available. However, the vice-versa is not always true. High reliability contributes to high availability, but it is possible to achieve a highly available system by minimizing the repair time and ensuring that spares are always available when needed.
Efficiency
Efficiency considers an operation that runs in a distributed manner and delivers a set of items as result. Then, the efficiency can be measured using - response time (or latency), which denotes the delay to obtaining the first item, and throughput (or bandwidth) which denotes the number of items delivered in a given time unit (ex. a second).
This comes down to the following unit costs:
- A number of messages are sent globally by the nodes of the system, regardless of the message size.
- The size of messages represents the volume of data exchange.
Serviceability/ Manageability
Serviceability/ Manageability talks about:
- How easy it is to operate or maintain.
- The time taken during repairs, as the system will not be available for use during repair.
- The ease of diagnosing and understanding the problem, the ease of making updates/modifications. Early detection of fault/faults can significantly lower or in some cases, avoid system downtime.
Reference: